.webp)
Structured interview questions: examples and a working template
A working bank of structured interview questions, plus the rubric that turns them into hiring decisions you can defend.

Why most interviews still run on instinct
Most interviewers walk out of a 45-minute conversation feeling they have a read on a candidate. They usually feel that whether or not the conversation contained any useful information. Dana, Dawes and Peterson (2012) showed this with uncomfortable directness: across three studies, interviewers maintained their confidence in candidates even when those candidates had been instructed to answer questions according to a random system. The participants did not notice. They built a narrative anyway.
That is the unhappy truth behind several decades of interview-validity research. The largest meta-analysis in the field, McDaniel, Whetzel, Schmidt and Maurer (1994), pulled together 245 validity coefficients from a combined sample of 86,311 individuals. The pattern they found was unambiguous: how an interview is run shapes how well it predicts performance, and most working interviews are not run in a way that predicts much at all.
The fix is not exotic. It is a structured interview - the same questions, in the same order, scored against the same rubric, by interviewers trained to do it the same way. The evidence on its predictive validity is unusually consistent for a social-science finding.
This article does not relitigate that evidence at length. The job here is practical: what structured interview questions actually look like, the four types worth running, a worked example bank for managers and individual contributors, and a scoring rubric you can lift. By the end you should be able to design something usable for a real role on Monday morning, with the failure modes named honestly.
What "structured" actually means
A structured interview is four things at once. You ask every candidate the same questions. You ask them in the same order. You score the answers against a rubric the panel agreed on before anyone walked in. And the people doing the scoring have been trained to apply that rubric the same way. Take any one of those out and you have something that looks structured from a distance and behaves like opinion up close. The U.S. Office of Personnel Management's the four pillars that move an interview from opinion to evidence describes exactly this combination, and it is the operating definition this article will use.
The academic version of the same point has more components and the same shape. Campion, Palmer and Campion (1997) reviewed the literature and identified 15 components of interview structure. Some affect the content of the interview - how questions are derived, how prompts are limited, how ancillary information is controlled. Others affect the evaluation - whether each answer is rated, whether the rating scales are anchored, whether interviewers compare notes between candidates. Adding components increases reliability, validity, and (mostly) candidates' sense that the process is fair.
In practice, most teams have one or two of the four pillars and call themselves structured. They have a list of questions, perhaps. The order drifts depending on who is in the room. The "rubric" is a number from 1 to 5 with no agreed meaning. Training is a 20-minute call before the first panel. This is the modal state of structured interviewing in scaling companies, and it explains why teams who think they have a structured process get unstructured-interview results.
One useful clarification before the question types. A behavioural interview is not a separate thing from a structured interview - it is one common variant inside the broader structured family, the one that asks candidates to describe past episodes rather than imagine future ones. The next section is about which question types earn their place and why.
The four question types worth running
People Also Ask wants to know the six types of structured interview questions. There is no canonical six. There are guides that list six or seven types, others that list four or five, and the disagreement is mostly about how finely you slice the same underlying ideas. Skills, problem-solving and motivation questions are usually job-knowledge or behavioural questions in different clothes. The most useful working set is four.
Behavioural questions ask the candidate to describe a real episode from their working life. "Tell me about a time you gave a direct report feedback they did not want to hear. What did you say, and what changed afterwards?" The form is recognisable because most interview guides have absorbed it; the source is McClelland (1998) and the Behavioural Event Interview, which asks candidates to describe what they said, thought, felt and did across specific episodes. The premise is that past behaviour predicts future behaviour better than self-description does, and the evidence supports it.
Situational questions ask what a candidate would do in a hypothetical scenario. "A direct report misses two deadlines in a row and tells you they are overloaded. The data does not back that up. What do you do this week?" Situational questions are particularly useful for early-career candidates who do not yet have a back catalogue of episodes to describe. They are also harder to fake than people assume, because the follow-up question reveals whether the candidate has thought about the trade-offs or is improvising.
Job-knowledge questions verify that the candidate can actually do the technical part of the job. "How do you decide between coaching a struggling direct report and putting them on a performance plan?" for a manager. "Read this 200-word brief, what would you ask the stakeholder before estimating?" for a product manager. Without job-knowledge questions you ask the same person to demonstrate skill in answers to questions you never asked if they had.
Background questions establish what the candidate has actually done. Largest team led, largest budget owned, technical decisions made and what they would repeat. These sound boring and they are; they are also the cheapest way to spot a CV that does not survive a follow-up question. Campion, Palmer and Campion (1998) make the broader point that "better questions" - hypothetical, past-behaviour, background and job-knowledge - lift validity through job-relatedness, while open-ended impression-forming questions add error variance and very little signal.
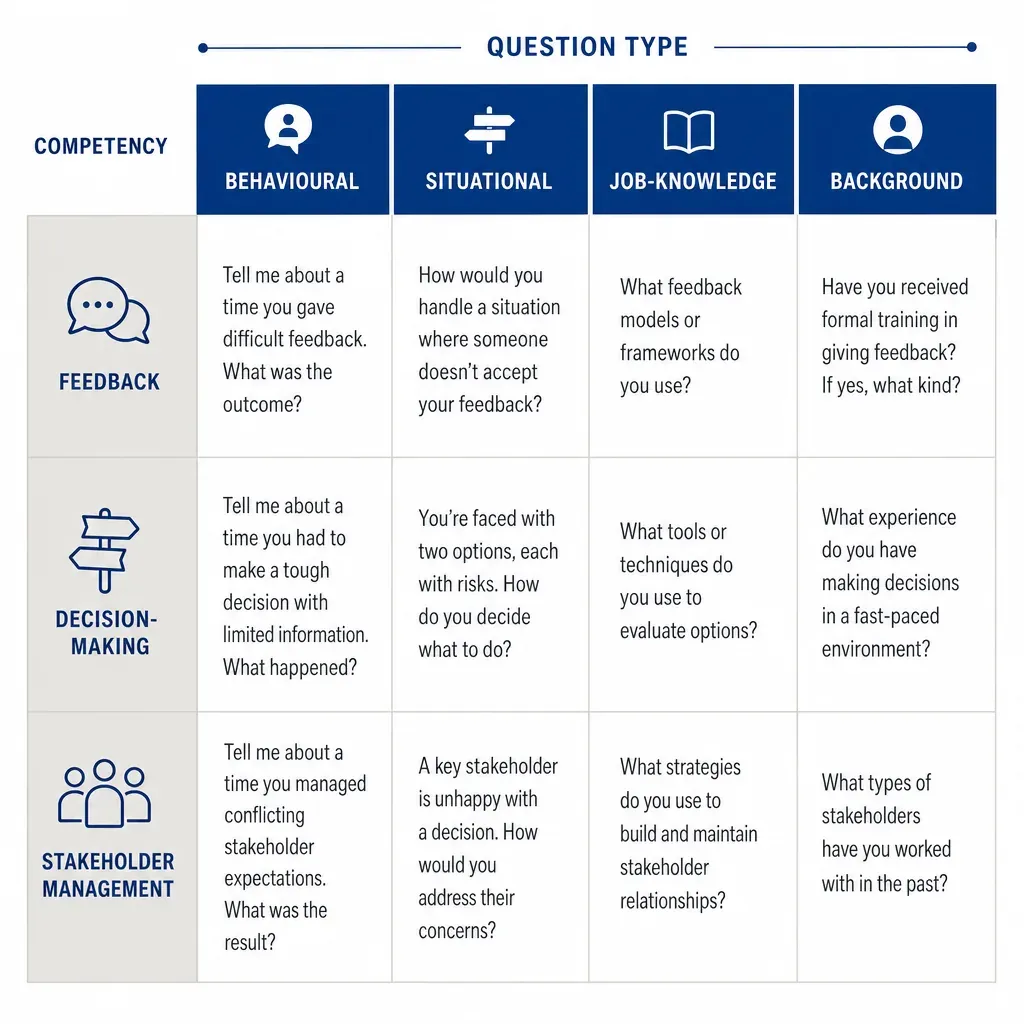
A working bank of example questions
Here is a small, opinionated bank you can lift, organised by competency and showing each of the four question types in action. The temptation is to design twenty competencies and a hundred questions; resist it. Two questions per competency, six competencies per role - around twelve questions in total - is the working upper bound that most public-sector and well-run private-sector structured interviews settle on.
For a people-management role:
- Behavioural (giving feedback). Tell me about a time you gave a direct report feedback they were not expecting. What did you say, what did they do, and what changed in the following weeks?
- Situational (managing under-performance). A direct report misses two deadlines in a row and tells you they are overloaded. Their work output suggests they are not. What do you do this week, and what do you do next month?
- Job-knowledge (the manager's tool kit). How do you decide whether a struggling direct report needs more coaching or a structured performance plan? What signals push you one way or the other?
- Background (track record). What is the largest team you have led, and what changed under your leadership that would not have changed under someone else's?
For an individual contributor:
- Behavioural (ownership). Tell me about a problem you owned start to finish in your last role. What was the brief, what did you do, and what was the result you would point at as evidence?
- Situational (scope creep). A senior stakeholder asks you for an additional piece of scope two days before a deadline that the team is already tight on. How do you handle the conversation?
- Job-knowledge (the discipline). A real artefact from the role - a brief, a dataset, a snippet of code, a draft strategy. Read it, talk us through what you would ask before starting work, and what you would do first.
- Background (technical decisions). Walk us through a technical or design decision you made in the last 12 months. What were the alternatives, what trade-off did you accept, and what would you do differently?
Past-behaviour answers tend to ramble unless candidates are guided to the STAR framework for past-behaviour responses - Situation, Task, Action, Result. You do not need to brief candidates on STAR explicitly; you can pull them back to it with one prompt ("what was the result?") when the answer drifts. Interviewers should know the framework so they probe consistently across candidates rather than letting one person tell a story for ten minutes while another is cut off at three.
Scoring: the rubric is the work
Good questions get most of the credit and almost none of the leverage. The leverage lives in the scoring rubric. Standardising the questions without standardising how answers are judged still leaves you with opinion, dressed up.
The numbers are clear enough that they are worth quoting. Wiesner and Cronshaw (1988) reanalysed 150 validity coefficients and reported corrected validities of 0.20 for unstructured individual interviews, 0.63 for structured individual interviews, and 0.64 for structured board interviews using consensus ratings. Note where the lift came from. Putting more interviewers in the room ("board") barely moved the needle. Adding structure - including the scoring rubric - did the heavy lifting. The structure effect dwarfs the panel effect. This is one reason adding a third interviewer to a panel that does not score consistently rarely helps.
A good rubric looks like a behaviourally-anchored rating scale, not just a number from one to five. A 1, a 3, and a 5 each describe an observable behaviour. Interviewers do not have to remember what a 4 "means" because the scale tells them.
Worked example for a "gives clear feedback" competency:
- 1 - Below the bar. Talks about feedback as a manager's job in the abstract. No example. Or describes feedback as soft, framed as "I told them they were doing fine."
- 3 - At the bar. A recent specific example. Names the person and the issue. Frames the feedback as observation rather than judgement, and can describe the recipient's reaction.
- 5 - Above the bar. A recent specific example. The candidate's framing was already clear. The feedback the recipient acted on, what changed afterwards, and what the candidate would do differently next time. The episode reads like the candidate has a working method for this.

Anchored rating scales are one of the highest-leverage components in Campion, Palmer and Campion (1997)'s framework, alongside training interviewers to use them. The reason is mundane: people score consistently when the scale tells them what each level looks like, and inconsistently when it does not. The work of building the rubric is the work of agreeing what good looks like for the role - which is the conversation hiring teams should be having anyway, and usually only have when an offer goes wrong.
Installing this in a real hiring team
All of which leaves the practical question. You have a question bank you trust and a rubric you can defend. The harder problem is making sure that the manager interviewing the candidate next Thursday actually uses both - the same way the manager interviewing the candidate the Thursday after next will. Standardisation is what compounds. It is also what disappears the moment hiring volume goes up and the calendar fills.
This is the gap HireSchool exists to close. HireSchool is a self-guided digital programme called the Structured Hiring Method. It is delivered through video content and a learning management system. Customers buy access and run it themselves; their hiring managers and panelists log in, work through the material, and leave with a hiring process the team can run consistently from one role to the next. There is nobody from HireSchool sitting in your panels. The point is to install the practice inside your own team so the practice belongs to you.
Three components of the programme map onto the work this article has described. The first is codified scorecards - the rubric, written down once for each role family, used by every interviewer who scores against it. The second is behavioural interviewing training, so panelists ask the same questions in the same order and probe consistently when an answer drifts off the STAR scaffold. The third is decision management - what scores actually decide who gets hired, agreed before the panel walks in rather than negotiated afterwards. The underlying standard is First Past the Post: the first candidate above the bar wins, no holding out for a unicorn. That last one is the part most teams find hardest, and it is also where most of the hiring debt comes from when it is missing.
Together these matter most when a hiring team grows past the size where one founder or one head of people can sit in on every interview. The rubric on a Notion page only works if everyone reads it, applies it the same way, and stops freelancing the moment the calendar gets tight. That consistency is what the programme codifies and trains for.
HireSchool is not consultancy. It is not an applicant tracking system. It is not a recruiting agency. The team installs the practice; the programme codifies the method.
If the rubric and question bank in this article look like the kind of thing you would actually run, but you suspect that a month from now half the panel will be running something else, you can explore the Structured Hiring Method programme. The programme is the layer that turns a sensible question bank into a process every interviewer in the company runs the same way - which is the only version of structured interviewing that holds its predictive validity over time.
The honest caveats
The literature on structured interviewing does not show a single tidy effect size. It shows a high mean and a high variance: structured interviews work much better than unstructured ones on average, but real-world implementations vary enormously. Recent commentary in Industrial and Organizational Psychology makes this point at length, framing the gap between mean validity and what real implementations deliver as the field's most under-studied issue. The headline claim "structured interviews are twice as predictive" is true on average and routinely untrue in any given hiring team.
The most common failure mode is not exotic. Rubrics exist but interviewers freestyle half the time, especially under time pressure, especially when the candidate is "obviously" strong, especially when the loudest voice in the panel had a different impression. The discipline of running the process the same way every time is what separates structured-on-paper from structured-in-fact.
A second caveat: the questions are only as good as the role analysis behind them. An off-the-shelf bank applied to a role you have not analysed is closer to unstructured than structured. The competencies have to come from the actual work, not from a generic "good employee" template, and that is true whether you build them yourself or borrow them. Levashina, Hartwell, Morgeson and Campion (2013) make the broader case that structure without job analysis loses most of its predictive validity.
Structured interview questions are not magic. They are the part of hiring most worth getting right, because so much of the rest of the process depends on them. The decisions you make in 30 minutes of conversation set the trajectory for someone's first 18 months at the company, and a panel that runs the same way every time gives you a fighting chance of explaining how those decisions were made. That is the modest claim, and it is the one the evidence will support.



